pg-transactional-outbox
Version:
A PostgreSQL based transactional outbox and inbox pattern implementation to support exactly once message processing (with at least once message delivery).
978 lines (835 loc) • 62.7 kB
Markdown
# pg-transactional-outbox
The `pg-transactional-outbox` library implements the transactional outbox and
transactional inbox pattern based on PostgreSQL. It ensures that outgoing
messages are only sent when your code successfully commits your transaction. On
the receiving side, it ensures that a message is stored exactly once and that
your handler marks the message only as done when your code finishes
successfully.

_Message delivery via the PostgreSQL-based transactional outbox pattern
(generated with Midjourney)_
Install the library
[npmjs | pg-transactional-outbox](https://www.npmjs.com/package/pg-transactional-outbox)
e.g. via
```
npm i pg-transactional-outbox
```
or
```
yarn add pg-transactional-outbox
```
**Table of contents:**
- [Context](#context)
- [The patterns](#the-patterns)
- [What is the transactional outbox pattern](#what-is-the-transactional-outbox-pattern)
- [What is the transactional inbox pattern](#what-is-the-transactional-inbox-pattern)
- [Using PostgreSQL Logical Replication](#using-postgresql-logical-replication)
- [Using database polling](#using-database-polling)
- [The pg-transactional-outbox library overview](#the-pg-transactional-outbox-library-overview)
- [Database server](#database-server)
- [Database setup](#database-setup)
- [Implementing the transactional outbox producer](#implementing-the-transactional-outbox-producer)
- [Implementing the transactional inbox consumer](#implementing-the-transactional-inbox-consumer)
- [Message format](#message-format)
- [Strategies](#strategies)
- [Message handler strategies](#message-handler-strategies)
- [Replication listener strategies](#replication-listener-strategies)
- [Polling listener strategies](#polling-listener-strategies)
- [Testing](#testing)
# Context
A service often needs to update data in its database and send events (when its
data was changed) and commands (to request some action in another service). All
the database operations can be done in a single transaction. But sending the
message must (most often) be done as a separate action. This can lead to data
inconsistencies if one or the other fails.
Storing a product order in the Order Service but failing to send an event to the
shipping service can lead to products not being shipped - case 1 in the diagram
below. This would be the case when the database transaction succeeded but
sending the event failed. Sending the event first and only then completing the
database transaction does not fix it either. The products might then be shipped
but the system would not know the order for which the shipment was done (case
2).
Similar issues exist in the Shipment Service. The service might receive a
message and start the shipment but fail to acknowledge the message. The message
would then be re-sent and if the operation is not done in an idempotent way
there might be two shipments for a single order (case 3). Or the message is
acknowledged as handled but submitting the database transaction fails. Then the
message is lost and the customer will not receive the goods (case 4).

_Potential messaging pitfalls_
One way to solve this would be to use distributed transactions using a two-phase
commit (2PC). PostgreSQL supports the 2PC but many message brokers and event
streaming solutions like RabbitMQ and Kafka do not support it. And even if they
do, it would often not be good to use 2PC. Distributed transactions need to lock
data until all participating services commit their second phase. This works
often well for a small number of services. But with a lot of (micro) services
communicating with each other this often leads to severe bottlenecks.
# The Patterns
When delivering messages we mostly have three different delivery guarantees:
- **At most once** - which is the most basic variant. It tries to send the
message but if it fails the message is lost.
- **At least once** - this is the case when we guarantee that the message will
be delivered. But we make no guarantee on how often we send the message. At
least once - but potentially multiple times.
- **Exactly once** - this is on the delivery itself most often considered to not
be possible. Multiple mechanisms need to play together to ensure that a
message is sent (at least) once but guaranteed to be processed (exactly) once.
The transactional outbox and transactional inbox pattern provide such a
combination that guarantees exactly-once **processing** (with at least once
delivery).
You might want to use the transactional inbox pattern in scenarios where the
reliability and atomicity of message processing are important, such as in an
event-driven architecture where the loss or duplication of a message could have
significant consequences.
This diagram shows the involved components to implement both the transactional
outbox and the transactional inbox pattern. The following chapters explain the
components and the interactions in detail.
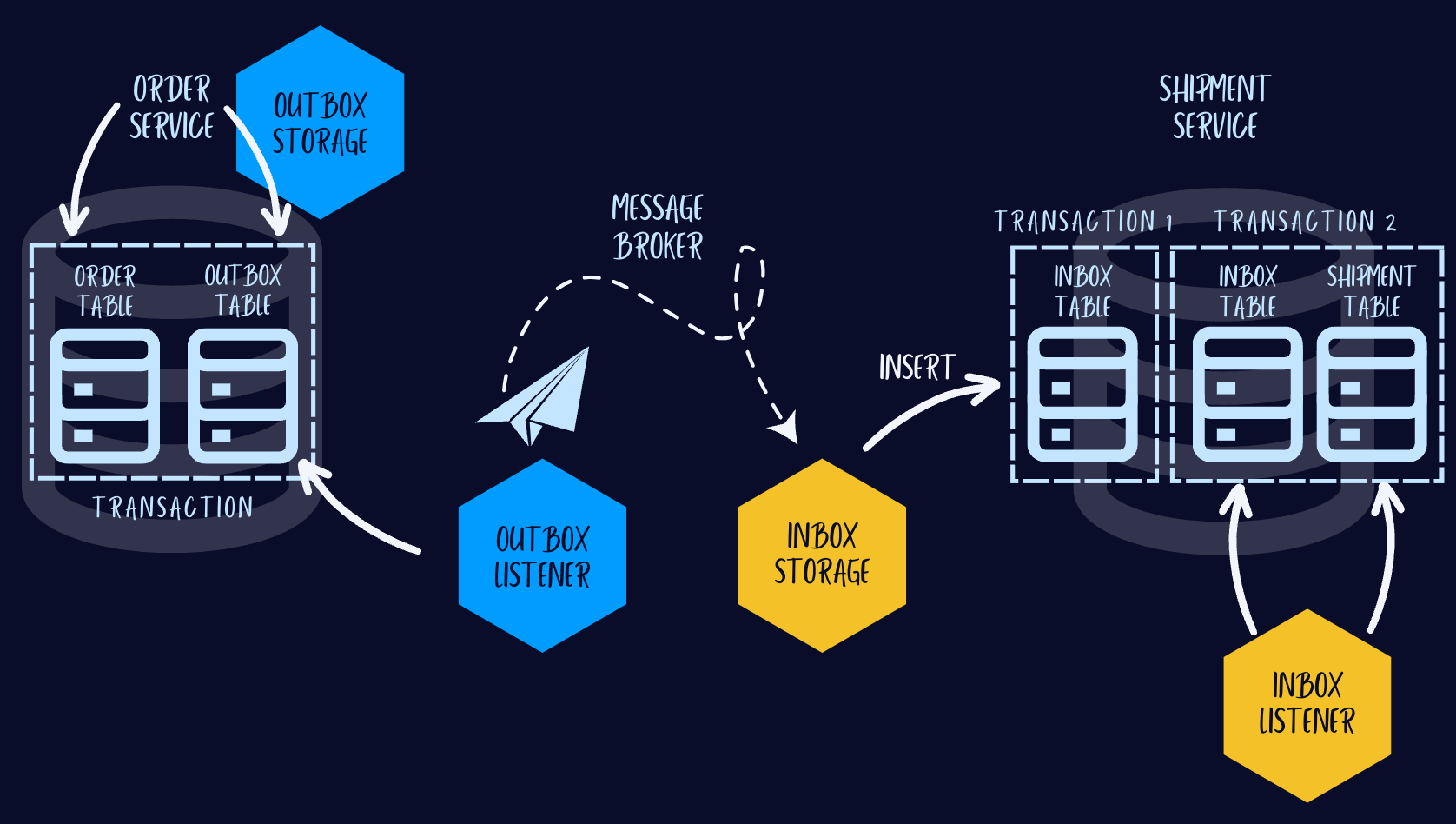
_Components involved in the transactional outbox and inbox pattern
implementation_
## What is the transactional outbox pattern
The transactional outbox pattern is a design pattern that allows you to reliably
"send" messages within the context of a database transaction. It is used to
ensure that messages are only sent if the transaction is committed and that they
are not lost in case of failure.
The transactional outbox pattern uses the following approach to guarantee the
exactly-once processing (in combination with the transactional inbox pattern):
1. Some business logic needs to update data in its database and send a message
(e.g. with details of the changes).
2. It uses a database transaction to add all of the business data changes on the
one hand and it inserts the details of the message that should be sent into
an "outbox" table within the same database transaction. The message includes
the necessary information to send the message to the intended recipient(s),
such as the message payload and the destination topic or queue. This ensures
that either everything is persisted in the database or nothing. The
`outbox storage` component in the above diagram encapsulates the logic to
store messages in the outbox table.
3. A background process notices when a new entry appears in the "outbox" table
and loads the message data.
4. Now the message can be sent. This can be done via a message broker, an event
stream, or any other option. The outbox table entry is then marked as
processed _only_ if the message was successfully sent. In case of a
message-sending error, or if the outbox entry cannot be marked as processed,
the message is sent again. The `outbox listener` is responsible for this
step.
The third step can be implemented via the Polling-Publisher pattern or the
Transactional Log Tailing pattern.
- **Polling-Publisher**: a polling listener queries the outbox table on a
(short) interval. When unprocessed messages are found they can be sent.
- **Transactional Log Tailing** (also called Capture-Based Log Tailing) reads
from the transactional log or change stream that contains the changes to the
outbox table. For PostgreSQL, this is handled with the Write-Ahead Log (WAL)
and logical replication which is depicted in the diagram and described further
down in more detail. Using this approach, the transactional outbox pattern can
be implemented with minimal impact on the database, as the WAL tailing process
does not need to hold locks or block other transactions.
You can read more about the transactional outbox pattern in this
[microservices.io](https://microservices.io/patterns/data/transactional-outbox.html)
article.
## What is the transactional inbox pattern
The _transactional inbox_ pattern targets the message consumer side of the
process. It is a design pattern that allows you to reliably receive messages and
process each message exactly once.
The transactional inbox pattern uses the following approach to guarantee the
exactly-once processing (in combination with the transactional outbox pattern):
1. A message is sent to a message broker (such as RabbitMQ) and stored in a
queue, event stream, or any other location.
2. A background process consumes messages from the queue and inserts them into
an "inbox" table in the database. The process uses the unique message
identifier to store the message in the inbox as the primary key. This ensures
that each message is only written once to this database table even if the
same message was delivered multiple times (deduplication). The
`inbox storage` component from the above diagram handles this step.
3. A consumer process receives the messages that were stored in the inbox table
and processes them. It uses a transaction to store all the service-relevant
data and mark the inbox message in the inbox table as processed. If an error
happens during message processing the message can be retried for a
configurable amount of attempts. This is done by the `inbox listener` in the
above diagram.
Step three can be implemented again as a Polling-Publisher or via the
Transactional Log Tailing approach like for the outbox pattern.
## Using PostgreSQL Logical Replication
PostgreSQL logical replication is a method that offers the possibility of
replicating data from one PostgreSQL server to another PostgreSQL server or
other consumer. It works by streaming the changes that are made to the data in a
database in a logical, row-based format, rather than replicating at the physical
storage level.
This is achieved by using a feature called "Logical Replication Slot", which
allows the primary PostgreSQL server (publisher) to stream changes made to a
specific table or set of tables to a replication client. The client can then
apply these changes to its own database (effectively replicating the data). Or
more generally the client can use those changes for any kind of
updates/notifications.
The replication process begins with the creation of a replication slot on the
primary database server. A replication slot is a feature on the PostgreSQL
server that persists information about the state of replication streams.
Replication slots serve to retain WAL (Write-Ahead Logging) files on the
publisher, ensuring that the required logs for replication are not removed
before the subscribing server received them. It keeps track of the last WAL
location that was successfully sent to the subscriber, so that upon reconnection
after a disconnect, replication can resume from that position without missing
any data. In the transactional outbox/inbox pattern case, the outbox and inbox
tables are replicated.
A publisher prepares and sends the stream of data changes from specified tables
to the subscribers. For the transactional outbox and inbox scenario the outbox
and inbox tables are configured for publication. The publisher creates a set of
changes that need to be replicated based on inserts, updates, and deletes on the
published tables. These changes are sent in the form of "WAL records"
(Write-Ahead Log records). Publications are used in conjunction with
subscriptions to set up logical replication from the publisher to the
subscriber.
When the subscriber (client) connects to the publisher, it specifies the name of
the logical replication slot it wants to use. The publisher uses this
information to start streaming changes from the point in the WAL that is stored
in the replication slot. As the subscriber receives changes, it updates the
position of the replication slot on the publisher to keep track of where it is
in the stream. The position defines the last data record that the client
successfully consumed and acknowledged. It is not possible to acknowledge only
specific WAL records - everything up to this position is acknowledged.
In this way, the publisher and subscriber can maintain a consistent position in
the replication stream, allowing the subscriber to catch up with any changes
that may have occurred while it was disconnected.

_Components involved in the transactional outbox and inbox logical replication
implementation_
## Using database polling
The second approach handles messages when they are added to the transactional
inbox or outbox is to use database polling. Your node.js application will query
those tables at regular intervals to see if new messages arrived. When
unprocessed outbox messages are found they can be sent via e.g. a message
broker. For inbox messages, a message handler will be executed to handle the
message.
This setup is purely based on the database and does not use logical replication:

_Components involved in the transactional outbox and inbox logical replication
implementation_
## Logical replication vs. polling
The logical replication and the polling listeners have different advantages and
disadvantages. Please check the following table to get an overview and also the
next section about considerations to operate such a solution.
Both listeners can be used interchangeably with minor differences on the
concurrency strategies. Switching from one listener type to another during
development time requires not much code changes. Switching in production is easy
from logical replication to polling. The way around you have to make sure that
the replication slot is generated upfront. Then let the listener process the
latest messages and restart the service. Some messages will be attempted twice
but this is handled by the checks on the processed/abandoned at database fields.
| Area | Logical Replication | Polling |
| ------------------ | -------------------------------------------------------------------- | ------------------------------------------------------------------------------------ |
| Scaling | Only a single instance can connect to the replication slot. | Multiple instances can poll from the same table. |
| Lag | Receives new messages immediately. | Must poll on a (short) timeout for new messages. Can be improved with LISTEN/NOTIFY. |
| DB load | Listening to new messages does not use the database itself. | Polling the database for new messages puts load on the database. |
| Setup | Logical replication must be enabled. A replication role is required. | No special settings are needed. |
| Message priority | Will receive messages sequentially. Picking newer messages is hard. | Can implement any selection algorithm based on segments or other fields. |
| Sequential order | Guaranteed sequential ordering same as transactions were committed. | Sequential processing only on created_at date which may not be unique. |
| Quick Retries | Receives messages again immediately when some error ocurred. | The locked_until colum might not be reset on error. Next retry needs to wait. |
| Scheduled Retries | Processes messages sequentially. May delete and re-add message. | Can use the locked_until field to schedule messages for a later point in time. |
| DB degrading | When a replication slot is not active disk space may run out. | When messages are not deleted the polling will slow down over time. |
| Migration/Failover | To guarantee same LSNs only some migration types are available. | Can use any available migration or failover option. |
## Operational notes
General considerations for both approaches:
- Like any other service functionality it is important to monitor the
functionality of the listeners. This could be done by checking the amount of
unprocessed messages in the inbox/outbox. Or by sending and receiving a test
message and time the duration.
### Logical replication approach
The following points are important when operating the logical replication
approach for using the transactional outbox and inbox:
- When the logical replication approach is used there must be a consumer that
reads from the WAL and acknowledges the LSN numbers. If the consumer is down
for longer periods the database server must retain the WAL files which can
fill up the disk and bring down the full database server. Good monitoring is
mandatory. You can check the maximum wal size, the retention period, and the
wal file size configuration values. PostgreSQL will do a roll-over of old WAL
files if you configure a maximum size. This would mean old message
notifications are lost. Removing and adding all messages again in the order of
the created_at field could be used as a recovery strategy.
- The name of a replication slot must be unique at the PostgreSQL server level.
- Migrating a database when using the logical replication approach is tricky. It
tracks the processing progress based on the LSN numbers of the database. When
the database is migrated or a failover happens the replication slot must be
manually recreated on the new instance. Possible solutions:
- [Patroni configured slots](https://patroni.readthedocs.io/en/latest/dynamic_configuration.html)
- [pg_failover_slots](https://github.com/EnterpriseDB/pg_failover_slots)
- Manually: Create the replication slot on the new database server. Stop your
application so no new inbox/outbox messages arrive. Switch the service to
the new database. Messages that arrived during that time will be pushed to
the listener. But as the messages were marked as processed, the message
processing will stop.
- The replication role has built-in permissions to list and delete all
replication slots on the database server. If the database server is shared it
is not possible to secure against replication slot deletions.
- With the logical replication approach, it is not that important to delete
outbox and inbox messages quickly as the tables are not queried much besides
based on their unique ID.
### Polling approach
The polling approach has not that many special considerations. It will put
higher load on the database due to the polling approach but is generally easier
to maintain.
- On the polling listener, it is important to delete messages from the outbox
and inbox tables to increase polling performance. A tradeoff must be taken
between the performance by deleting messages and the message deduplication
possibilities by keeping the messages longer.
# The pg-transactional-outbox library overview
This library implements the transactional outbox and inbox pattern using a
PostgreSQL server. It implements both the Transactional Log Tailing approach via
the PostgreSQL Write-Ahead Log (WAL) and the polling listener.
You can use the library in your node.js projects that use a PostgreSQL database
as the data store and some message sending/streaming software (e.g. RabbitMQ or
Kafka).
## Database server
This library was tested with PostgreSQL servers starting from version 14. But it
should most likely work with versions starting from version 12.
### Polling Listener Setup
No special extensions or settings are required for the polling listener setup.
### Logical Replication Setup
For the logical replication setup, the PostgreSQL database server itself must
have the `wal_level` configured as `logical`. This enables the use of the WAL to
be notified on e.g. new inserts. You should also check the `max_wal_senders`,
the `max_wal_size`, and the `min_wal_size` settings to contain values that match
your architecture. Setting a large size could consume/max out the disk space.
Setting the value too low could lead to lost events in case your WAL consumer is
down for a longer duration. An example `postgres.conf` file is shown in the
`./infra` folder. This folder includes also a `docker-compose.yml` file to set
up a PostgreSQL server with these default values (and a RabbitMQ instance for
running the examples).
This library uses the standard PostgreSQL logical decoding plugin `pgoutput`.
This plugin is directly part of PostgreSQL since version 9.4. Other alternatives
would be `wal2json` or `decoding-json` but those are not used in this library.
## Database setup
To support the transactional outbox and inbox implementation you need to create
an outbox and an inbox table in your PostgreSQL database. You should create two
database roles: one for the message handler and one for the message listener.
You must grant those roles permission to the tables.
The inbox and the outbox tables and the corresponding structure are identical.
They can reside in the same database if your service uses both the outbox and
the inbox pattern which is often the case for distributed services.
You can manually create the required database structure or (suggested) use this
library to help you with this task.
The easiest way is to use the CLI tool to generate the SQL scripts and the .ENV
settings file for you. You can find the CLI tool in the `./examples/setup/`
folder. It will guide you by asking the required values from you.
```shell
yarn dev:watch
```
You can find the example SQL scripts in the following two files which you can
also use and adjust.
- `examples/setup/out/example-trx-polling.sql` (for polling listener)
- `examples/setup/out/example-trx-replication.sql` (for replication listener)
If you do not want to run the generated SQL scripts e.g. as part of your
application migration you can also set up the database from a node.js
application. The library offers you a `DatabaseSetup` helper to create the
required tables etc. in your database. You can do this from within your codebase
based on the configuration settings that you provide. Both the inbox and outbox
structure are created in the same way so you call the same functions but with
different configurations.
### Logical Replication Setup
If you use the logical replication approach, the database listener role needs
the replication permission. As this role has a lot of rights it is not advised
to give the replication permission to the same role that reads and mutates the
business-relevant data.
> **NOTE**: the replication slot name is database **server** unique! This means
> if you use the transactional inbox pattern on multiple databases within the
> same PostgreSQL server instance you must use different replication slot names
> for each of them. When creating a new replication slot you must run that SQL
> script in its own database transaction.
### Polling Listener Setup
For the polling approach, you could use a single database role but it is still
advised to use two separate database roles. The roles should not have the
`REPLICATION` permission.
## Implementing the transactional outbox producer
The following code shows the producer side of the transactional outbox pattern.
It shows the usage in the outbox scenario to either use the logical replication
approach with `initializeReplicationMessageListener` or the polling approach
with `initializePollingMessageListener`. They receive the messages when an
outbox message is written to the outbox table. And the
`initializeMessageStorage` generator function to store outgoing messages in the
outbox table.
```TypeScript
import process from 'node:process';
import { Pool } from 'pg';
import {
GeneralMessageHandler,
PollingListenerConfig,
ReplicationListenerConfig,
TransactionalMessage,
createReplicationMutexConcurrencyController,
getDefaultLogger,
initializeMessageStorage,
initializePollingMessageListener,
initializeReplicationMessageListener,
} from 'pg-transactional-outbox';
(async () => {
const logger = getDefaultLogger('outbox');
// Initialize the actual message publisher e.g. publish the message via RabbitMQ
const messagePublisher: GeneralMessageHandler = {
handle: async (message: TransactionalMessage): Promise<void> => {
// In the simplest case the message can be sent via inter process communication
process.send?.(message);
},
};
// You can also use ENV variables via getOutboxReplicationListenerSettings and
// getOutboxPollingListenerSettings to create the settings objects.
const dbListenerConfig = {
host: 'localhost',
port: 5432,
user: 'db_outbox_listener',
password: 'db_outbox_listener_password',
database: 'pg_transactional_outbox',
};
const baseSettings = {
dbSchema: 'public',
dbTable: 'outbox',
enableMaxAttemptsProtection: false,
enablePoisonousMessageProtection: false,
};
const replicationConfig: ReplicationListenerConfig = {
outboxOrInbox: 'outbox',
dbListenerConfig,
settings: {
...baseSettings,
dbPublication: 'pg_transactional_outbox_pub',
dbReplicationSlot: 'pg_transactional_outbox_slot',
},
};
const pollingConfig: PollingListenerConfig = {
outboxOrInbox: 'outbox',
dbListenerConfig,
settings: {
...baseSettings,
nextMessagesBatchSize: 5,
nextMessagesFunctionName: 'next_outbox_messages',
nextMessagesPollingIntervalInMs: 250,
},
};
// Initialize and start the listening for outbox messages. This listeners
// receives all the outbox table inserts from the WAL or via polling. It
// executes the messagePublisher handle function with every received outbox
// message. It cares for the at least once delivery.
let shutdownListener: () => Promise<void>;
if (process.env.LISTENER_TYPE === 'replication') {
const [shutdown] = initializeReplicationMessageListener(
replicationConfig,
messagePublisher,
logger,
{
concurrencyStrategy: createReplicationMutexConcurrencyController(),
messageProcessingTimeoutStrategy: (message: TransactionalMessage) =>
message.messageType === 'ABC' ? 10_000 : 2_000,
},
);
shutdownListener = shutdown;
} else {
const [shutdown] = initializePollingMessageListener(
pollingConfig,
messagePublisher,
logger,
{
messageProcessingTimeoutStrategy: (message: TransactionalMessage) =>
message.messageType === 'ABC' ? 10_000 : 2_000,
},
);
shutdownListener = shutdown;
}
// Initialize the message storage function to store outbox messages. It will
// be called to insert the outgoing message into the outbox table as part of
// the DB transaction that is responsible for this event.
const storeOutboxMessage = initializeMessageStorage(
replicationConfig,
logger,
);
// The actual business logic generates in this example a new movie in the DB
// and wants to reliably send a "movie_created" message.
const pool = new Pool({
host: 'localhost',
port: 5432,
user: 'db_outbox_handler',
password: 'db_outbox_handler_password',
database: 'pg_transactional_outbox',
});
const client = await pool.connect();
try {
// The movie and the outbox message must be inserted in the same transaction.
await client.query('START TRANSACTION ISOLATION LEVEL SERIALIZABLE');
// Insert the movie (and query/mutate potentially a lot more data)
const result = await client.query(
`INSERT INTO public.movies (title) VALUES ('some movie') RETURNING id, title;`,
);
// Define the outbox message
const message: TransactionalMessage = {
id: new Crypto().randomUUID(),
aggregateType: 'movie',
messageType: 'movie_created',
aggregateId: result.rows[0].id,
payload: result.rows[0],
createdAt: new Date().toISOString(),
};
// Store the message in the outbox table
await storeOutboxMessage(message, client);
// (Try to) commit the transaction to save the movie and the outbox message
await client.query('COMMIT');
client.release();
} catch (err) {
// In case of an error roll back the DB transaction - neither movie nor
// the outbox message will be stored in the DB now.
await client?.query('ROLLBACK');
client.release(true);
throw err;
}
await shutdownListener();
})();
```
> **Please note:** This library offers to automatically delete outbox messages
> from the outbox table. Keeping them for a while can be good to ensure that a
> message is only generated once. But most often this is more of a concern on
> the inbox side. Please configure your duration on how long the messages should
> stay in this table. This can be seconds but also some minutes. You can define
> different age thresholds for processed messages, abandoned ones, and a general
> max age setting. To be safe you can add logic to not send messages anymore
> that are older than these defined durations.
> As an alternative you could also create a `outbox_archive` table and write a
> script to move the messages into that table instead of deleting them.
### Outbox Storage
The outbox storage is used to store the message that should later be sent into
the `outbox` database table. The `initializeMessageStorage` is initialized to
store outbox messages:
- `message`: the outbox message with a unique message ID and other relevant
data. It contains the message payload that is used on the receiving side to
act on such a message.
- `client`: the database client with an open database transaction to handle both
the business logic database changes as well as store the outgoing message
within that transaction.
### Outbox Listener
The `initializeReplicationMessageListener` is used to create and start the
logical replication-based listener that gets notified when a new outbox message
is written to the outbox table. It takes the message publisher instance as an
input parameter and calls it to send out messages. Other parameters are the
`config` object, a `logger` instance and an optional strategies object to
fine-tune and customize specific aspects of the outbox listener.
The second option is to use the `initializePollingMessageListener` to use the
database polling approach to query for unprocessed outbox messages. It uses the
same handler to send out the message and the same logger. It has a (partly)
different configuration object and can optionally define also different
strategies.
You can build the configuration object from your code. Alternatively, you can
use `process.env` variables to provide the configuration values.
The easiest way to generate the .ENV files is to use the CLI tool which also
generates the SQL scripts file. You can find the CLI tool in the
`./examples/setup/` folder.
```shell
yarn dev:watch
```
You can find the example ENV files here:
- `examples/setup/out/example-trx-polling.env` (for polling listener)
- `examples/setup/out/example-trx-replication.sql` (for replication listener)
All ENV variables can use one of the following three prefixes:
- `TRX_OUTBOX_<variable>` - those variables are used to build the
outbox-specific settings for the desired listener.
- `TRX_INBOX_<variable>` - those variables are used to build the inbox-specific
settings for the desired listener.
- `TRX_<variable>` - those variable values are used for both the outbox and
inbox settings when no outbox or inbox-specific value is provided.
| \<PREFIX\> + Variable Name | Type | Default | Description |
| ---------------------------------------------- | ------- | -------- | -------------------------------------------------------------------------------------------------------------------------------------------------- |
| TRX_DB_SCHEMA | string | "public" | The database schema name where the table is located. |
| TRX_MESSAGE_PROCESSING_TIMEOUT_IN_MS | number | 15000 | Stop the message handler after this time has passed. |
| TRX_MAX_ATTEMPTS | number | 5 | The maximum number of attempts to handle a message. With max 5 attempts a message is handled once initially and up to four more times for retries. |
| TRX_MAX_POISONOUS_ATTEMPTS | number | 3 | The maximum number of times a message should be attempted which was started but did not finish (neither error nor success). |
| TRX_MESSAGE_CLEANUP_INTERVAL_IN_MS | number | 300000 | Time in milliseconds between the execution of the old message cleanups. Set it to zero to disable automatic message cleanup. |
| TRX_MESSAGE_CLEANUP_PROCESSED_IN_SEC | number | 604800 | Delete messages that were successfully processed after X seconds. |
| TRX_MESSAGE_CLEANUP_ABANDONED_IN_SEC | number | 1209600 | Delete messages that could not be processed after X seconds. |
| TRX_MESSAGE_CLEANUP_ALL_IN_SEC | number | 5184000 | Delete all old messages after X seconds. |
| TRX_OUTBOX_DB_TABLE | string | "outbox" | The name of the database outbox table. |
| TRX_OUTBOX_ENABLE_MAX_ATTEMPTS_PROTECTION | boolean | false | Enable the max attempts protection. |
| TRX_OUTBOX_ENABLE_POISONOUS_MESSAGE_PROTECTION | boolean | false | Enable the max poisonous attempts protection. |
| TRX_INBOX_DB_TABLE | string | "inbox" | The name of the database inbox table. |
| TRX_INBOX_ENABLE_MAX_ATTEMPTS_PROTECTION | boolean | true | Enable the max attempts protection. |
| TRX_INBOX_ENABLE_POISONOUS_MESSAGE_PROTECTION | boolean | true | Enable the max poisonous attempts protection. |
The replication listener approach supports the following variables in addition
to the above ones:
| \<PREFIX\> + Variable Name | Type | Default | Description |
| ----------------------------------- | ------ | ---------------------------------- | ---------------------------------------------------------------------------------------------------- |
| TRX_RESTART_DELAY_IN_MS | number | 250 | When there is a message handling error, how long the listener should wait to restart the processing. |
| TRX_RESTART_DELAY_SLOT_IN_USE_IN_MS | number | 10000 | If the replication slot is in used, how long the listener should wait to connect again. |
| TRX_OUTBOX_DB_PUBLICATION | string | "transactional_outbox_publication" | The name of the PostgreSQL publication that should be used for the outbox. |
| TRX_OUTBOX_DB_REPLICATION_SLOT | string | "transactional_outbox_slot" | The name of the PostgreSQL replication slot that should be used for the outbox. |
| TRX_INBOX_DB_PUBLICATION | string | "transactional_inbox_publication" | The name of the PostgreSQL publication that should be used for the inbox. |
| TRX_INBOX_DB_REPLICATION_SLOT | string | "transactional_inbox_slot" | The name of the PostgreSQL replication slot that should be used for the inbox. |
The polling listener approach supports the following variables in addition to
the above ones:
| \<PREFIX\> + Variable Name | Type | Default | Description |
| ---------------------------------------- | ------ | ---------------------- | ------------------------------------------------------------------------------------ |
| TRX_NEXT_MESSAGES_FUNCTION_SCHEMA | string | "public" | The database schema of the next messages function. |
| TRX_NEXT_MESSAGES_BATCH_SIZE | number | 5 | The (maximum) amount of messages to retrieve in one query. |
| TRX_NEXT_MESSAGES_LOCK_IN_MS | number | 5000 | How long the retrieved messages should be locked before they can be retrieved again. |
| TRX_NEXT_MESSAGES_POLLING_INTERVAL_IN_MS | number | 500 | How often should the next messages function be executed. |
| TRX_OUTBOX_NEXT_MESSAGES_FUNCTION_NAME | string | "next_outbox_messages" | The database function name to get the next batch of outbox messages. |
| TRX_INBOX_NEXT_MESSAGES_FUNCTION_NAME | string | "next_inbox_messages" | The database function name to get the next batch of inbox messages. |
An example ENV file can then be:
```shell
TRX_DB_SCHEMA=messaging
TRX_MESSAGE_PROCESSING_TIMEOUT_IN_MS=30000
TRX_OUTBOX_DB_TABLE=outbox
TRX_OUTBOX_ENABLE_MAX_ATTEMPTS_PROTECTION=false
TRX_OUTBOX_ENABLE_POISONOUS_MESSAGE_PROTECTION=false
TRX_INBOX_DB_TABLE=inbox
TRX_INBOX_ENABLE_MAX_ATTEMPTS_PROTECTION=true
TRX_INBOX_MAX_ATTEMPTS=5
TRX_INBOX_ENABLE_POISONOUS_MESSAGE_PROTECTION=true
TRX_INBOX_MAX_POISONOUS_ATTEMPTS=3
...
```
### Message Publisher
The message publisher is responsible for the actual transport of the message to
the recipient(s). It receives the outbox `message` with all the fields -
including the metadata. Based on the metadata the message publisher should send
out the message. The messaging publisher logic or the used system is responsible
for guaranteeing at least once message delivery. You can find a RabbitMQ-based
implementation in the examples folder.
## Implementing the transactional inbox consumer
A minimalistic example code for the consumer of the published message using the
transactional inbox pattern is included below. The main functions are the
`initializeInboxMessageStorage` function that is used by the actual message
receiver like a RabbitMQ-based message handler to store the incoming message
(which was based on an outbox message) in the inbox table.
The other central functions are the `initializeReplicationMessageListener` or
the `initializePollingMessageListener`. The replication listener uses one
database connection based on a user with replication permission to receive
notifications when a new inbox message is created. The polling listener queries
the database regularly for new inbox messages.
The code uses a second database connection to open a transaction, load the inbox
message from the database and lock it, execute the message handler
queries/mutations, and finally mark the inbox message as processed in the
database.
```TypeScript
import { Pool } from 'pg';
import {
DatabaseClient,
IsolationLevel,
PollingListenerConfig,
ReplicationListenerConfig,
TransactionalMessage,
TransactionalMessageHandler,
createReplicationMultiConcurrencyController,
ensureExtendedError,
executeTransaction,
getDefaultLogger,
initializeMessageStorage,
initializePollingMessageListener,
initializeReplicationMessageListener,
} from 'pg-transactional-outbox';
/** The main entry point of the message producer. */
(async () => {
const logger = getDefaultLogger('inbox');
// You can also use ENV variables via getInboxReplicationListenerSettings and
// getInboxPollingListenerSettings to create the settings objects.
// This configuration is used to start a transaction that locks and updates
// the row in the inbox table that was found from the inbox table. This connection
// will also be used in the message handler so every select and data change is
// part of the same database transaction. The inbox database row is then
// marked as "processed" when everything went fine.
const dbHandlerConfig = {
host: 'localhost',
port: 5432,
user: 'db_inbox_handler',
password: 'db_inbox_handler_password',
database: 'pg_transactional_inbox',
};
// Configure the replication role to receive notifications when a new inbox
// row was added to the inbox table. This role must have the replication
// permission.
const dbListenerConfig = {
host: 'localhost',
port: 5432,
user: 'db_inbox_listener',
password: 'db_inbox_listener_password',
database: 'pg_transactional_inbox',
};
const baseSettings = {
dbSchema: 'public',
dbTable: 'inbox',
enableMaxAttemptsProtection: true,
enablePoisonousMessageProtection: true,
};
const replicationConfig: ReplicationListenerConfig = {
outboxOrInbox: 'inbox',
dbHandlerConfig,
dbListenerConfig,
settings: {
...baseSettings,
dbPublication: 'pg_transactional_inbox_pub',
dbReplicationSlot: 'pg_transactional_inbox_slot',
},
};
const pollingConfig: PollingListenerConfig = {
outboxOrInbox: 'inbox',
dbListenerConfig,
settings: {
...baseSettings,
nextMessagesBatchSize: 5,
nextMessagesFunctionName: 'next_inbox_messages',
nextMessagesPollingIntervalInMs: 250,
},
};
// Create the database pool to store the incoming inbox messages
const pool = new Pool(replicationConfig.dbHandlerConfig);
pool.on('error', (err) => {
logger.error(ensureExtendedError(err, 'DB_ERROR'), 'PostgreSQL pool error');
});
// Initialize the inbox message storage to store incoming messages in the inbox
const storeInboxMessage = initializeMessageStorage(replicationConfig, logger);
// Initialize the message receiver e.g. based on RabbitMQ
// In the simplest scenario use the inter process communication:
process.on('message', async (message: TransactionalMessage) => {
await executeTransaction(
await pool.connect(),
async (client): Promise<void> => {
await storeInboxMessage(message, client);
},
IsolationLevel.ReadCommitted,
);
});
// Define an optional concurrency strategy to handle messages with the message
// type "ABC" in parallel while handling other messages sequentially based on
// their `segment` field value.
const concurrencyStrategy = createReplicationMultiConcurrencyController(
(message) => {
switch (message.messageType) {
case 'ABC':
return 'full-concurrency';
default:
return 'segment-mutex';
}
},
);
// Declare the message handler
const movieCreatedHandler: TransactionalMessageHandler = {
aggregateType: 'movie',
messageType: 'movie_created',
handle: async (
message: TransactionalMessage,
client: DatabaseClient,
): Promise<void> => {
// Executes the message handler logic using the same database
// transaction as the inbox message acknowledgement.
const { payload } = message;
if (
typeof payload === 'object' &&
payload !== null &&
'id' in payload &&
typeof payload.id === 'string' &&
'title' in payload &&
typeof payload.title === 'string'
) {
await client.query(
`INSERT INTO public.published_movies (id, title) VALUES ($1, $2)`,
[payload.id, payload.title],
);
}
},
handleError: async (
error: Error,
message: TransactionalMessage,
_client: DatabaseClient,
retry: boolean,
): Promise<void> => {
if (!retry) {
// Potentially send a compensating message to adjust other services e.g. via the Saga Pattern
logger.error(
error,
`Giving up processing message with ID ${message.id}.`,
);
}
},
};
// Initialize and start the inbox listener
let shutdownListener: () => Promise<void>;
if (process.env.LISTENER_TYPE === 'replication') {
const [shutdown] = initializeReplicationMessageListener(
replicationConfig,
[movieCreatedHandler],
logger,
{
concurrencyStrategy,
messageProcessingTimeoutStrategy: (message: TransactionalMessage) =>
message.messageType === 'ABC' ? 10_000 : 2_000,
messageProcessingTransactionLevelStrategy: (
message: TransactionalMessage,
) =>
message.messageType === 'ABC'
? IsolationLevel.ReadCommitted
: IsolationLevel.RepeatableRead,
},
);
shutdownListener = shutdown;
} else {
const [shutdown] = initializePollingMessageListener(
pollingConfig,
[movieCreatedHandler],
logger,
{
messageProcessingTimeoutStrategy: (message: TransactionalMessage) =>
message.messageType === 'ABC' ? 10_000 : 2_000,
messageProcessingTransactionLevelStrategy: (
message: TransactionalMessage,
) =>
message.messageType === 'ABC'
? IsolationLevel.ReadCommitted
: IsolationLevel.RepeatableRead,
},
);
shutdownListener = shutdown;
}
await shutdownListener();
})();
```
> **Please note:** This library offers to automatically delete inbox messages
> from the inbox table. Keeping them for a while is required to ensure that a
> message is only processed once (due to multiple deliveries or replay attacks).
> Please configure your duration on how long the messages should stay in this
> table. This can be a few minutes but also some days. You can define different
> age thresholds for processed messages, abandoned ones, and a general max age
> setting. To be safe you can add logic to not process messages anymore that are
> older than these defined durations.
> As an alternative you could also create a `inbox_archive` table and write a
> script to move the messages into that table instead of deleting them.
### Message receiver
The message receiver is the counterpart to the message publisher. It receives
the transferred outbox message and has to store it in the inbox table. It is the
responsibility of the receiver to guarantee that the message is written to the
inbox table via the inbox storage functionality. It can try it multiple times if
needed. You can find a RabbitMQ-based implementation in the examples folder.
### Message Storage
When a message is received it must use the inbox storage functionality to store
the message. The `initializeInboxMessageStorage` is used to create an inbox
storage instance. The inbox storage takes the incoming message and stores it in
the inbox table.
### Inbox Listener
The `initializeReplicationMessageListener` is used to create and start the
logical replication-based listener that gets notified when a new inbox message
is written to the inbox table. It takes the message publisher instance as an
input parameter and calls it to send out messages. Other parameters are the
`config` object, a `logger` instance and an optional strategies object to
fine-tune and customize specific aspects of the inbox listener.
It uses the same logic and settings as the outbox listener. Please check that
section for further explanations and available configuration values.
The inbox listener starts the actual message handling logic. This is most often
more complex and longer running. Therefor it is suggested to always enable the
maximum attempts protection and the poisonous message protection.
### Message Handler
The message handler is a component that defines how to process messages. You can
provide a general one (`GeneralMessageHandler`) that handles all messages. This
is often used for the outbox message handler which sends all messages to the
same message broker. It has the following interface:
- `handle`: A function that contains the custom business logic to handle an
inbox message. It receives two parameters: `message` and `client`. The
`message` parameter is an object that contains the message id, payload, and
metadata. The `client` parameter is a database client that is part of a
transaction to safely handle the inbox message. The function should return a
promise that resolves when the message is successfully processed, or rejects
with an error if the message cannot be processed. The error will cause the
message to be retried later.
- `handleError`: An optional function that contains the custom business logic to
handle an error that was caused by the `handle` function. It receives four
parameters: `error`, `message`, `client`, and `attempts`. The `error`
parameter is the error that was thrown in the `handle` f